作業幫檢索服務基于 Fluid 的計算存儲分離實踐
隨著數據規模的持續增長和海量計算需求的涌現,傳統的數據處理架構在彈性、成本和效率上面臨諸多挑戰。作業幫作為一家專注于教育科技的公司,其檢索服務需要處理海量的教育內容和用戶行為數據,這對系統的存儲與計算能力提出了更高的要求。在此背景下,作業幫檢索服務團隊基于 Fluid 這一開源項目,成功實踐了計算存儲分離的架構,顯著提升了系統的可擴展性和資源利用效率。
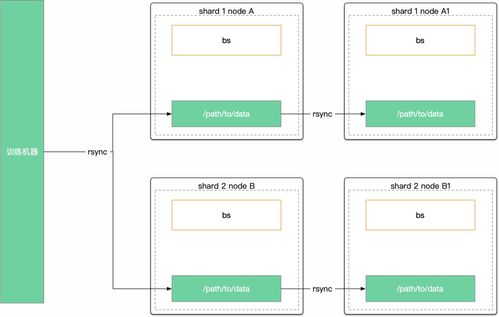
計算存儲分離是一種將計算資源與數據存儲資源解耦的設計理念。在傳統架構中,計算節點通常與存儲節點緊密耦合,這導致資源擴展不靈活、數據共享困難以及運維復雜性增加。而借助 Fluid,作業幫能夠實現數據在分布式環境下的高效緩存與調度,讓計算任務可以就近訪問數據,從而降低網絡開銷,提升整體性能。
在具體實踐中,作業幫檢索服務首先利用 Fluid 的數據預加載和自動緩存功能,將熱點數據預先分布到計算節點本地,避免了頻繁的遠程數據讀取。通過 Fluid 的動態資源分配機制,系統能夠根據檢索負載自動調整緩存策略和計算資源,確保高并發場景下的穩定響應。這一方案不僅減少了數據訪問延遲,還顯著降低了存儲成本,因為計算節點無需再維護獨立的存儲副本。
Fluid 的引入還簡化了作業幫檢索服務的運維管理。通過統一的控制平面,運維團隊可以輕松監控數據流動和緩存狀態,快速定位和解決潛在問題。這種架構還支持多租戶環境,使得不同業務線的檢索服務能夠安全、高效地共享底層存儲資源,進一步提升了資源利用率。
作業幫檢索服務基于 Fluid 的計算存儲分離實踐,不僅有效應對了海量數據處理帶來的挑戰,還為未來的業務擴展奠定了堅實的技術基礎。這一創新實踐展示了計算存儲分離在現代互聯網服務中的巨大潛力,也為其他面臨類似問題的企業提供了寶貴的參考經驗。
如若轉載,請注明出處:http://www.hicom.net.cn/product/7.html
更新時間:2026-02-24 09:19:58